

Human trafficking and labor exploitation are ancient problems that have evolved with each major leap in technology, from the agricultural revolution to the information age. But what if the right combination of people, data, and technology could help to tackle these problems on an unprecedented scale? With the emergence of generative AI models, which can create rich text and media from natural language prompts and real-world understanding, we are seeing new opportunities to advance the work of organizations that are leading this fight on the front lines.

One effort to combat trafficking is the Tech Against Trafficking (opens in new tab) accelerator program, in which tech companies collaborate with anti-trafficking organizations and global experts to help eradicate trafficking with technology. In the latest accelerator, Microsoft worked with Issara Institute (opens in new tab) and Polaris (opens in new tab) to explore how generative AI could help NGOs drive the ethical transformation of global supply chains. By aiming to reduce all forms and levels of worker exploitation, including but not limited to the most serious cases of human trafficking, these organizations aim to make systematic labor exploitation impossible to hide.
The main issue to contend with, however, is that it is all too easy for such practices to remain hidden, even across datasets that contain evidence of their existence. Many NGOs lack the resources to “connect the dots” at the necessary scale, and time spent on data work is often at the expense of direct assistance activities. Through the accelerator, we developed several first-of-their-kind workflows for real-world data tasks – automating the creation of rich intelligence reports and helping to motivate collective, evidence-based action. We are pleased to announce that we have now combined these workflows into a single system – Intelligence Toolkit (opens in new tab) – and published the code to GitHub for use by the broader community.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the first four episodes on demand.
Building on multi-stakeholder engagements
Since Microsoft co-founded Tech Against Trafficking (TAT) in 2018, we have worked with a range of UN agencies and NGOs to understand the challenges facing the anti-trafficking community, as well as opportunities for new research technologies (opens in new tab) to drive evidence-based action at scale. For example, our collaboration with IOM (UN Migration) (opens in new tab) in the 2019 TAT accelerator program (opens in new tab) resulted in new tools (opens in new tab) for private data release, as well as new open datasets (opens in new tab) for the community. However, while growing the shared evidence base enables better decision making and policy development, it is not sufficient. NGOs and other anti-trafficking organizations need time and resources to analyze such datasets, discover relevant insights, and write the intelligence reports that drive real-world action.
For the 2023-2024 TAT accelerator program, we worked with Issara and Polaris to understand the potential for generative AI to support such analysis within their own organizations and geographies of concern (South and Southeast Asia for Issara; Mexico and the U.S. for the Polaris Nonechka (opens in new tab) project). Using a combination of open and internal datasets, we developed and refined a series of proof-of-concept interfaces before sharing them for stakeholder feedback at the annual TAT Summit (opens in new tab), Issara Global Forum (opens in new tab), and NetHope Global Summit (opens in new tab) events. We learned many lessons through this process, helping to shape what community-oriented tool we should build, how to build it, and when it should be used:
- What: Use to automate analysis and reporting under expert supervision. For NGO staff members that need to divide their time between frontline assistance and data work, any tool that increases the efficiency and quality of data work can create more time for more effective assistance.
- How: Use an appropriate combination of statistical and generative methods. Generative AI excels at translating data summaries into narrative reports, but statistical methods are also important for identifying all the potential insights (e.g., patterns, clusters, networks) worth reporting.
- When: Use for individual-level case data and entity data. Worker voice data (e.g., employer grievances) creates the need to both protect the privacy of workers and connect data across employers in ways that reveal aggregate risk. Neither is well supported by existing data tools.
Developing Intelligence Toolkit as a gateway to generative AI
For the various intelligence-generating activities shared with us by Issara and Polaris, as well as prior accelerator participants, we developed interactive workflows supported by different combinations of statistical methods and generative AI. Each was developed as a lightweight, no-code user interface that supports the end-to-end process of data upload, preparation, analysis, and export. Our Intelligence Toolkit (opens in new tab) application combines six of these workflows with the most relevance to the broader community. Following the recent TAT showcase event (opens in new tab) that shared how this application was being used internally at both Issara and Polaris, we are pleased to announce the general availability of this software on GitHub (opens in new tab).
The six workflows currently supported are:
Data Synthesis generates differentially private datasets and summaries from case records
Our approach to private data release using synthetic data was first developed in the 2019 TAT accelerator program with IOM (UN Migration) (opens in new tab), and IOM recently used our existing open source tools to release the largest individual-level dataset (opens in new tab) on victims of trafficking that is both publicly available and protected by differential privacy. The synthetic datasets we generate retain the structure and statistics of the original sensitive datasets, but individual records do not represent actual people and the presence of any individual in the sensitive dataset is obscured by calibrated noise injected into the synthesis process.
Because other workflows require access to individual-level case data, we chose to integrate a streamlined approach to synthetic data generation in Intelligence Toolkit. This workflow was used by both Issara and Polaris to translate worker voice datasets into a form that could be shared with the community, as well as used in other workflows to guarantee that the resulting reports preserve privacy by design.
Attribute Patterns generates reports on attribute patterns detected in streams of case records
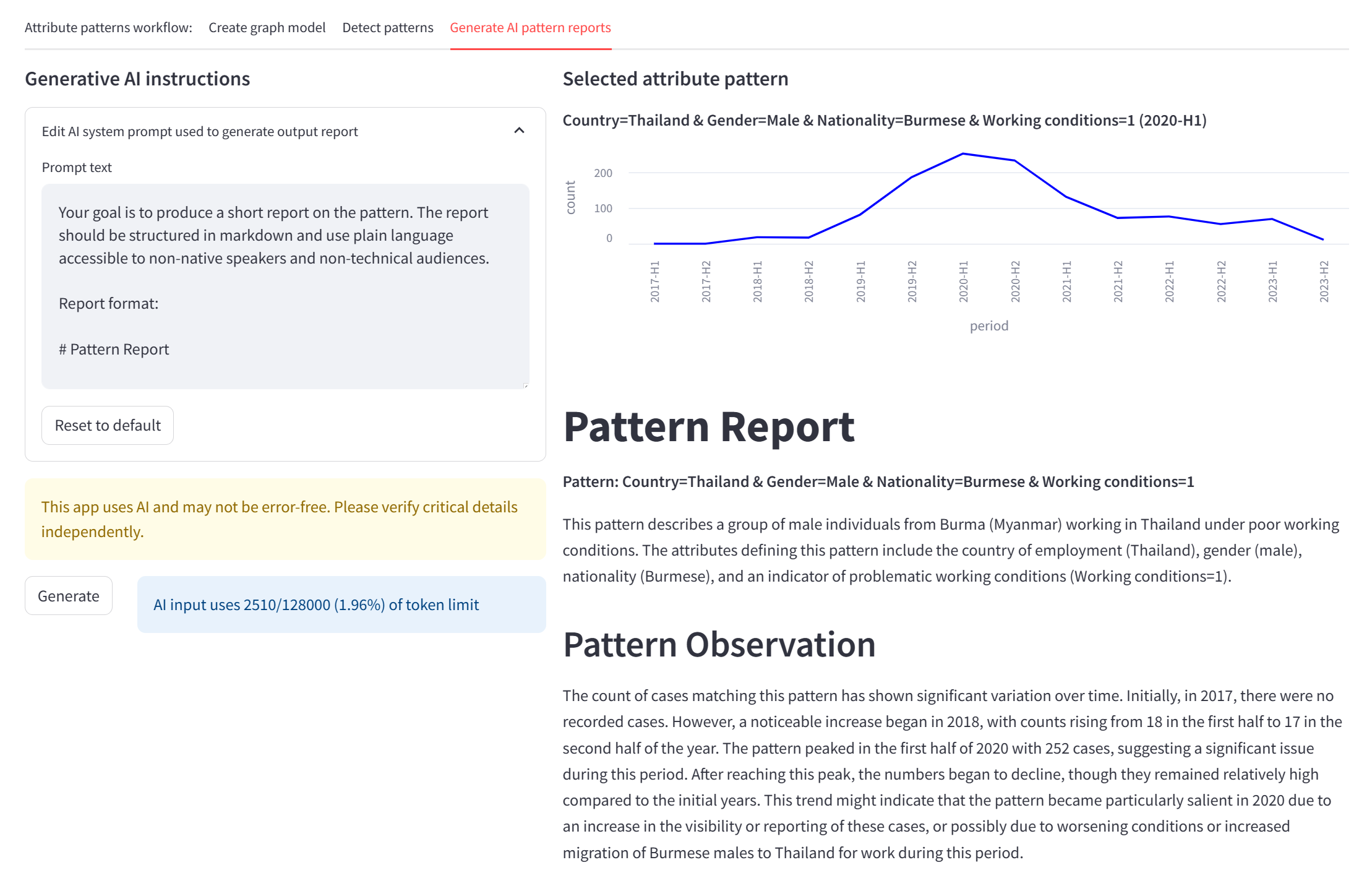
Our approach to detecting patterns of attributes in timestamped case records was first developed in the 2021 TAT accelerator program with Unseen UK, becoming one of our key tools for discovering insights in real-world data. This approach takes the common activity of “drilling down” into data dashboards by progressively selecting data values of interest and inverts it, generating all combinations of record attributes in each time period that appear interesting from a statistical perspective. It is vastly more efficient for domain experts to review lists of such patterns than to manually search for them one at a time.
Over the last year, we have collaborated with researchers at Johns Hopkins University and the University of Delaware to redesign this approach using Graph Fusion Encoder Embedding (opens in new tab). Unlike previous iterations, the Intelligence Toolkit workflow does not end with a list of attribute patterns. Instead, the analyst is invited to use generative AI to create reports that describe the pattern in narrative form, including what it represents, how it has varied over time, what other attributes co-occur with the pattern, what competing hypotheses could potentially explain the pattern, and what possible actions could be taken in response. In this and all subsequent workflows, users can edit the AI system prompts in ways that tailor reports to their specific needs. In the latest TAT accelerator, Issara used this workflow to discover and describe patterns of worker-reported grievances over time.
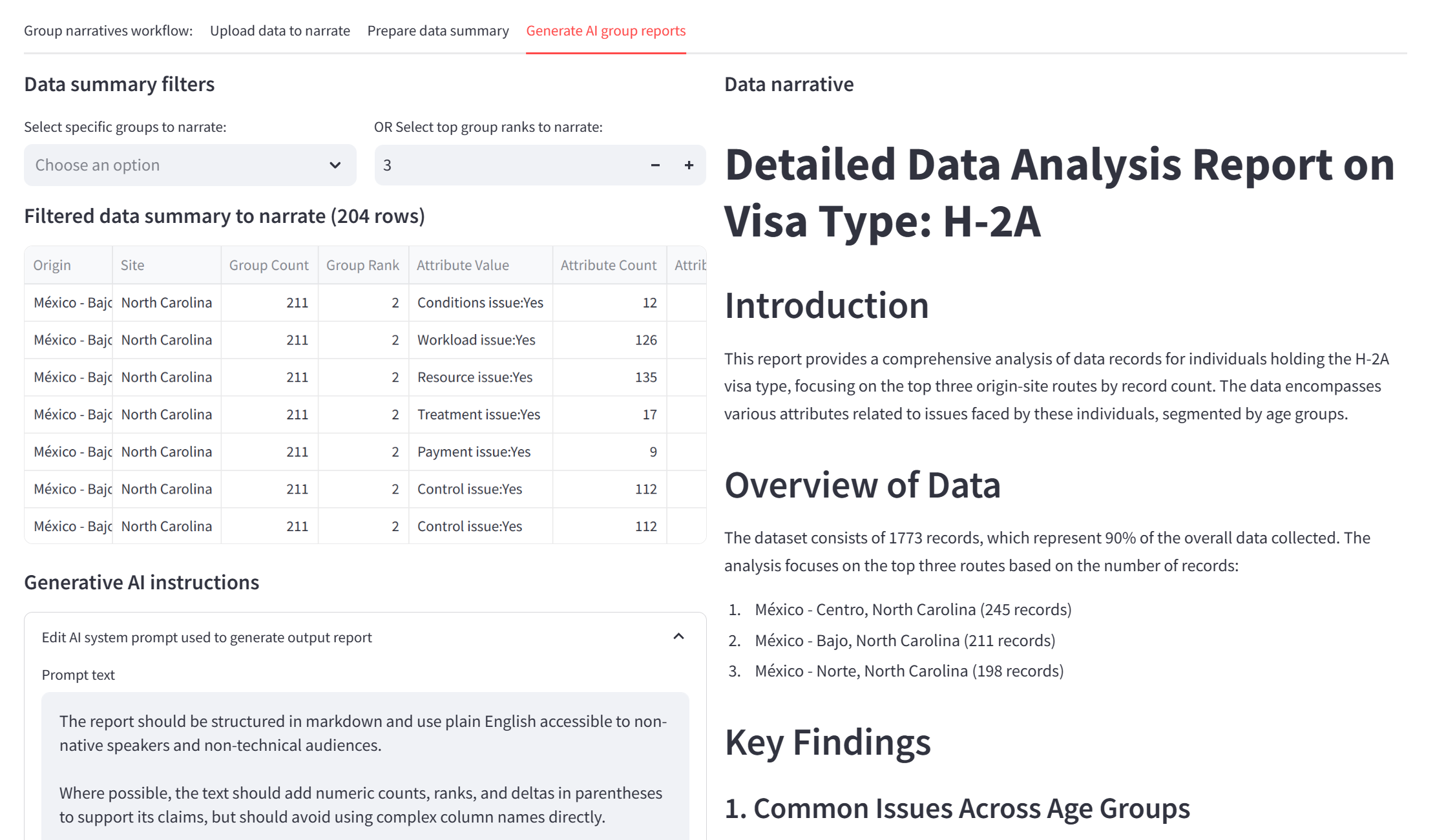
Group Narratives generates reports by defining and comparing groups of case records
This workflow aims to mimic the kinds of group-level comparisons that often lend structure to data narratives. For example, Polaris was interested in the different routes taken by H-2A visa (opens in new tab) workers from their place of origin to their place of work, the different kinds of grievances they reported, and how this varied by worker age. H-2A workers are highly reported as potential victims of labor trafficking to the National Human Trafficking Hotline (opens in new tab). This analysis was achieved by specifying a prefilter (H-2A visa), group definition (source-destination), comparison attributes (workload issues, conditions issues, etc.), and comparison window (age band). Given the resulting table of counts, ranks, and deltas, the user is then able to generate AI reports for specific groups, reports comparing the top N groups, and so on.
Record Matching generates reports on record matches detected across entity datasets
While previous workflows are independent of the identities of data subjects, in some cases such identities are the very focus of analysis. This often occurs not for case data linked to people, but for entity data linked to organizations. In the TAT accelerator, for example, Issara presented the problem of having two product databases describing many of the same employers, but without any links between common entities or any notion of a canonical identity. Connecting these two databases was critical for providing a comprehensive picture of each employer. The problem is also a general one; it arises whenever organizations seek to combine internal and external data sources on the same real-world entities (e.g., supplier companies).
Our solution was to create a record matching workflow based on the text embedding capabilities of large language models (LLMs). In addition to generating text, LLMs can also map arbitrary chunks of text into points in vector space, where similar vector positions represent similar semantics for the associated text chunks. Given the text embeddings of entity records taken from different databases, the tool is therefore able to identify groups of sufficiently similar entities so as to suggest a real-world match. Generative AI is then used to evaluate and prioritize these matches for human review and potential record linking.
Risk Networks generates reports on risk exposure for networks of related entities
Our risk networks workflow builds on our earlier work tackling corruption in the public procurement process, providing a streamlined interface for inferring entity relationships from shared attributes and then propagating red flag risks throughout the resulting networks. As in the record matching workflow, text embeddings are used to identify fuzzy matches between similar entity names and contact details that have different spellings or formats. Since LLMs tend to struggle with graph reasoning problems, the workflow computes and converts to text all shortest paths from flagged entities to the target entity of the network. These path descriptions then provide context for the LLM to reason about the potential for relationship-mediated risk exposure among entities with different degrees of relatedness and similarity. In the TAT accelerator, Polaris used this workflow together with open-source intelligence to analyze risk patterns within networks of employers recruiting temporary agricultural workers via the H-2A visa program.
Question Answering generates reports from an entity-rich document collection
Question answering is one of the leading use cases for generative AI, given the ability of LLMs to perform in-context learning over a set of input texts. For situations where the size of data to be queried exceeds the context window of the LLM, retrieval-augmented generation (RAG) can enable embedding-based matching of query text against input texts, before using the retrieved texts to help the LLM generate a grounded response. A major limitation of standard RAG, however, is that there is no guarantee that the retrieved texts provide a sufficiently comprehensive grounding to answer user questions, especially if the questions ask for summaries rather than facts. Our recent work (opens in new tab) using LLM-derived knowledge graphs as a RAG index aims to provide such grounding, but requires an extensive indexing process before any questions can be answered.
For Intelligence Toolkit, we therefore developed a new RAG approach for lightweight yet comprehensive question answering over collections of existing reports, targeted at NGOs wanting to leverage both their own report collections and those of other organizations (e.g., see collections of public reports from Issara (opens in new tab), Polaris (opens in new tab), Unseen (opens in new tab), and IOM (opens in new tab)). In this approach, text chunks that match the user’s question are first mined for question-answer pairs, before the question is augmented with any partial answers and embedded again alongside both unmined text chunks and the mined questions and answers. This process repeats until sufficient question-answer pairs have been extracted and matched against the augmented question, providing both an independent FAQ and grounding for the LLM answer to the original user question.

Continuing the fight against all kinds of societal threats
Intelligence Toolkit is our latest example of a human rights technology developed with global experts in the anti-trafficking community, yet applicable to a broad class of problems impacting societal resilience as a whole. As we work with TAT to help NGOs and other organizations use Intelligence Toolkit for their own data challenges, we hope to identify opportunities to refine and expand our initial workflows.
Across multiple stakeholder events, we have helped to raise awareness of generative AI and the real risks that misuse could pose to vulnerable populations. At the same time, generative AI has unprecedented potential to drive insight discovery, communication, and collective action across entire communities, in ways that are essential for tackling societal problems at scale. With Intelligence Toolkit, we have taken our first steps towards understanding how generative AI can be shaped into the tools that society most urgently needs.



