

Author: Shujie Liu
In recent years, the rapid advancement of AI has continually expanded the capabilities of Text-to-Speech (TTS) technology. Ongoing optimizations and innovations in TTS have enriched and simplified voice interaction experiences. These research developments hold significant potential across various fields, including education, entertainment, and multilingual communication, etc.
Traditional TTS systems, trained with high-quality clean data from the recording studio, still suffer from poor generalization. Speaker similarity and speech naturalness decrease dramatically for unseen speakers in the zero-shot scenario. To address this issue, researchers from MSR Asia developed VALL-E by introducing the LLM technique (training a model to predict the next token with large unsupervised sequential data) into the speech processing tasks. VALL-E is the first neural codec language model using discrete codes derived from an off-the-shelf neural audio codec model. It regards TTS as a conditional language model, emerging in-context learning capabilities. VALL-E is capable of synthesizing high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as a prompt. However, due to the auto-regressive modeling and the random sampling inference, VALL-E suffers from robustness and efficiency problems.
To deal with these problems, researchers proposed VALL-E 2, which leverages repetition-aware sampling and grouped code modeling techniques, achieving human parity in zero-shot TTS performance on LibriSpeech and VCTK datasets. Repetition aware sampling refines the original nucleus sampling process by accounting for token repetition in the decoding history. This approach not only stabilizes decoding but also circumvents the infinite loop issue observed in VALL-E. Additionally, grouped token modeling organizes codec codes into groups to effectively shorten the sequence length, which not only boosts inference speed but also addresses the challenges of long sequence modeling.
With these two techniques, VALL-E 2 surpasses previous systems in terms of speech robustness, naturalness, and speaker similarity. VALL-E 2 demonstrated constant ability to synthesize high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases.
VALL-E 2 paper: https://arxiv.org/abs/2406.05370 (opens in new tab)
VALL-E 2 demo: https://aka.ms/valle2 (opens in new tab)

Enhancing models with repetition-aware sampling and grouped token modeling
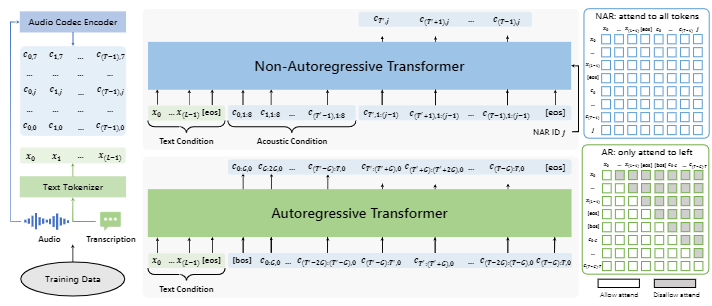
As illustrated in Figure 2, VALL-E 2 employs a hierarchical structure that is analogous to that of VALL-E. This structure comprises an Autoregressive (AR) codec language model and a Non-Autoregressive (NAR) codec language model. The AR model generates sequence of the first codec code for each frame in an autoregressive manner, while the NAR model generates each remaining code sequence based on the preceding code sequences in a non-autoregressive manner. Both models utilize the same Transformer architecture with a text embedding layer, a code embedding layer, a Transformer layer, and a code prediction layer. The AR model and NAR model have different attention mask strategies: the AR model uses the causal attention strategy, and the NAR model uses the full attention strategy.

In light of past experience, it has been observed that the random sampling used in VALL-E for inference can lead to instability in output. Although the probability of error tokens (red tokens in Figure 3) is low, they are still inevitable to be sampled due to the massive sampling steps. To stabilize the inference process, nucleus sampling is usually leveraged to sample tokens from the set of most probable tokens with a cumulative probability less than a preset threshold. The nucleus sampling method can reduce the occurrence of erroneous words, but it can also lead to the model generating silence output to avoid making mistakes.
To achieve a balance between random sampling and nucleus sampling, researchers proposed a repetition-aware sampling. Given the probability distribution predicted by the AR model, researchers first generate the target code by nucleus sampling with a pre-defined top-p value. Then, researchers calculate the repetition ratio of the predicted token in the preceding code sequence with a fixed window size. If the repetition ratio exceeds a pre-defined repetition threshold, researchers will replace the predicted target code with a randomly sampled code drawn from the original probability distribution. This repetition aware sampling method allows the decoding process to benefit from the stability of nucleus sampling while avoiding the infinite loop issue through the use of random sampling.
Meanwhile, it has been demonstrated thatthe autoregressive architecture of VALL-E is bound to the same high frame rate as the off-the-shelf audio codec model, which cannot be adjusted, resulting in a slow inference speed, especially for the inference of AR model. To speed up the inference process of VALL-E 2, researchers leveraged the grouped token modeling method, wherein the codec code sequence is partitioned into groups of a certain size and each group of codec codes is modeled as one frame. In the AR model, researchers leverage a group embedding layer to project the code embedding to the group embedding as the network input, and a group prediction layer for the prediction of codes in one group. In this way, we can get rid of the frame rate constraint of the off-the-shelf neural audio codec model and reduce the frame rate by integer multiples. It is not only beneficial for the inference efficiency but also the overall speech quality by mitigating the long context modeling problem.
Significant improvements in robustness, naturalness, and similarity

To show the performance of VALL-E 2, researchers conducted experiments on LibriSpeech and VCTK datasets, and compare the results with multiple baselines, in terms of robustness, naturalness, and similarity score. These scores are relative numbers calculated based on the results reported in the original papers, irrespective of differences in model architecture and training data. As illustrated in Figure 4, VALL-E 2 can significantly improve the performance compared with previous methods, and even achieves human parity zero-shot TTS performance for the first time. In this context, human parity indicates that the robustness, naturalness, and similarity metrics of VALL-E 2 surpass those of the ground truth samples ( WER(GroundTruth)-WER(VALL-E 2) >0, CMOS(VALL-E 2) – CMOS(GroundTruth) >0, and SMOS(VALL-E 2) -SMOS(GroundTruth)>0), meaning that VALL-E 2 can generate accurate, natural speech in the exact voice of the original speaker. It is important to note that this conclusion is drawn solely from experimental results on the LibriSpeech and VCTK datasets.
Through the introduction of repetition aware sampling and grouped code modeling, VALL-E 2 is capable of reliably synthesizing speech for complex sentences, including those that are challenging to read or contain numerous repeated phrases. The benefits of this work could support meaningful initiatives, such as generating speech for individuals with aphasia or people with amyotrophic lateral sclerosis.
Note: VALL-E 2 is purely a research project. Currently, we have no plans to incorporate VALL-E 2 into a product or expand access to the public. VALL-E 2 could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While VALL-E 2 can generate a voice similar to the natural voice, the similarity and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model. If you suspect that VALL-E 2 is being used in a manner that is abusive or illegal or infringes on your rights or the rights of other people, you can report it at the Report Abuse Portal (https://msrc.microsoft.com/report/ (opens in new tab)).
With the rapid development of AI technology, ensuring that these technologies are trustworthy remains a significant challenge. Microsoft has proactively implemented a series of measures to anticipate and mitigate the risks associated with AI. Committed to advancing AI development in line with human-centered ethical principles, Microsoft introduced six Responsible AI Principles in 2018: fairness, inclusiveness, reliability and safety, transparency, privacy and security, and accountability. To operationalize these principles, Microsoft subsequently released the Responsible AI Standards and established a governance framework to ensure that each team integrates these principles and standards into their daily work. Additionally, Microsoft continuously collaborates with researchers and academic institutions worldwide to advance the practice and technology of responsible AI.