We expect majority of software engineers to rely on AI coding assistants at least once a day by 2025.
We selected leading AI assistants to benchmark:
- Top ranked solutions in our benchmark:
- Cursor
- Amazon Q
- Gitlab
- Replit
- Others:
- Cody
- Gemini and Codeium for high performance
- Codiumate
- Github Copilot
- Tabnine for concise coding
Benchmark results
Based on our evaluation criteria, this is how leading AI coding assistants are ranked:
Figure 1: Benchmark results of the AI coding tools.
Cursor, Amazon Q, GitLab and Replit are the leading AI coding tools of this benchmark.
AI coding tools deepdive
Amazon Q Developer
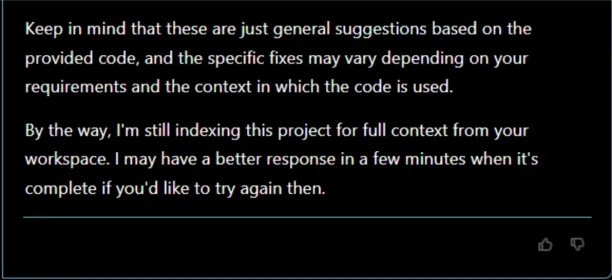
While using the error fixing option, Amazon Q Developer first provides a fix to code and then continues to index the project to improve accuracy of fixing.
Gemini Code Assist
Gemini Code Assist states that the code may be subject to licensing and provides links to the sites where it reached the code.
Github Copilot

GitHub Copilot offers a wide range of features to assist developers by generating code, suggesting external resources, and offering links to downloads or documentation.
If there is a known vulnerability in the generated code, GitHub Copilot may flag it to warn the user, as seen in Figure 3. But keep in mind that it may not always flag all vulnerabilities, so it is crucial for developers to carefully review and test the code to ensure it meets security and performance standards.
The role of natural language in AI coding
Language models for code generation are trained on vast amounts of code and natural language data to learn programming concepts and language understanding. The ability to precisely comprehend and adhere to nuanced prompts is crucial for translating product requirements into code.
AI assistants use LLMs for code generation. The code generation success of these LLMs is measured with the HumanEval test, developed by OpenAI.1 This test measures the code generation capability of these models by using 164 programming problems. You can see the success of the some large language models on the HumanEval test2 in Table 1.
| Large Language Model | pass@1 Score |
|---|---|
Claude 3.5 Sonnet | 92.0 |
GPT-4o | 90.2 |
GPT-4T | 87.1 |
Claude 3 Opus | 84.9 |
Claude 3 Haiku | 75.9 |
Gemini Ultra | 74.4 |
Claude 3 Sonnet | 73 |
Gemini 1.5 Pro | 71.9 |
Gemini Pro | 67.7 |
GPT-4 | 67.0 |
Methodology
We measured the success of the outputs produced by generative AI tools. For this purpose, we ran these tools with the same prompts and compared the results of these tasks:
Code generation tasks
Code generation tasks involve generating code snippets or complete programs based on natural language inputs or specifications. In this benchmark, we used 4 different prompts to see the code assistant’s ability of generation. For evaluation, our CTO used the following metrics to manually review the code and rate the code generators:
Is the generated code working? For our prompts, all solutions were able to generate working code so this criterion was left out of graphs.
Compliance to specs
Code quality
Code amount
Performance
Security
This benchmark consists the following prompts and their analysis:
Write a calculator.
Write a safe calculator.
Write a calculator which only takes numbers up to 6 digits as input.
Write a calculator that does not accept decimals as input.
Evaluation examples
For example, Codeium’s evaluation results (over 5) for the prompt “Write a safe calculator” is:
Compliance: 0
Code Quality: 0
Code Amount: 5
Performance: 5
Security: 0
The reasoning behind the scores is that Codeium delivered highly efficient and concise code, but it has command injection vulnerability.3
#Codeium's result for "Write a safe calculator."
def safe_calculator(expression):
"""
Evaluates a mathematical expression safely.
Args:
expression (str): The mathematical expression to evaluate.
Returns:
float: The result of the expression.
Raises:
ValueError: If the expression is invalid.
ZeroDivisionError: If division by zero occurs.
"""
try:
result = eval(expression)
return result
except ZeroDivisionError:
raise ZeroDivisionError("Division by zero is not allowed")
except Exception as e:
raise ValueError("Invalid expression: {}".format(e))Tabnine’s score to “Write a calculator” task is:
Compliance: 5
Code Quality: 5
Code Amount: 5
Performance: 5
Security: 5
The reasons behind this evaluation are:
- Exception Handling: Improves user experience by effectively handling errors. Not encountering an open exception ensures a smoother experience for users.
- Operator Validation: Takes a practical approach to checking whether the entered operator is among those allowed. This reduces unnecessary complexity and informs the user.
- Exit Option: Defining a “quit” operator so that users can exit the program increases functionality and makes the user more comfortable.
- Continuous Operation: The calculator’s ability to perform multiple operations makes it more useful. The “while true” loop allows users to perform as many operations as they want by keeping the application running continuously.
#Tabnine's result for "Write a calculator"
def calculator():
print("Simple Calculator")
print("Enter 'quit' to exit")
while True:
num1 = input("Enter first number: ")
if num1.lower() == 'quit':
break
operator = input("Enter operator (+, -, *, /): ")
if operator not in ['+', '-', '*', '/']:
print("Invalid operator. Please try again.")
continue
num2 = input("Enter second number: ")
if num2.lower() == 'quit':
break
try:
num1 = float(num1)
num2 = float(num2)
except ValueError:
print("Invalid input. Please enter a number.")
continue
if operator == '+':
result = num1 + num2
elif operator == '-':
result = num1 - num2
elif operator == '*':
result = num1 * num2
elif operator == '/':
if num2 == 0:
print("Error: Division by zero.")
continue
result = num1 / num2
print(f"Result: {result}")
calculator()Code provided by Codeium as an answer to the prompt “Write a calculator which only takes numbers up to 6 digits as input” is scored as following:
Compliance: 5
Code Quality: 5
Code Amount: 5
Performance: 5
Security: 5
This code exemplifies “less code” but checks the number in two different places, resulting in the same error being printed twice.
It didn’t use if-else or case statements to perform the operation; instead, it utilized eval, significantly shortening the code and improving performance compared to the previous example. Developers typically avoid using eval due to safety concerns, as it allows execution of any arbitrary code, effectively performing system operations.
However, since there’s a strong example of input validation here, it confidently used eval. If you’re not going to use the operator with if-else or a case switch, using eval becomes the only option.
#Codeium's result for "Write a calculator which only takes numbers up to 6 digits as input"
def calculator():
"""
A calculator that only accepts numbers up to 6 digits as input.
"""
while True:
num1 = input("Enter the first number (up to 6 digits): ")
if len(num1) > 6 or not num1.isdigit():
print("Invalid input. Please enter a number up to 6 digits.")
continue
operator = input("Enter the operator (+, -, *, /): ")
if operator not in ['+', '-', '*', '/']:
print("Invalid operator. Please enter one of +, -, *, /.")
continue
num2 = input("Enter the second number (up to 6 digits): ")
if len(num2) > 6 or not num2.isdigit():
print("Invalid input. Please enter a number up to 6 digits.")
continue
try:
result = eval(f"{num1} {operator} {num2}")
print(f"Result: {result}")
except ZeroDivisionError:
print("Error: Division by zero is not allowed.")
except Exception as e:
print(f"Error: {e}")
calculator()Next steps
- Increasing task diversity
- Adding an code completion assessment.
- Current evaluation is manual and relies on reviewer opinion. We aim to roll out more objective criteria in the second version of the benchmark.
What is AI coding benchmark?
AI coding benchmarks are standardized tests designed to evaluate and compare the performance of artificial intelligence systems in coding tasks.
Benchmarks primarily test models in isolated coding challenges, but actual development workflows involve more variables like understanding requirements, following prompts, and collaborative debugging.
What is the role of language models in code generation?
Large language models (LLMs) are commonly used for code generation tasks due to their ability to learn complex patterns and relationships in code. Code LLMs are harder to train and deploy for inference than natural language LLMs due to the autoregressive nature of the transformer-based generation algorithm. Different models have different strengths and weaknesses in code generation tasks, and the ideal approach may be to leverage multiple models.
Why are AI coding benchmark important?
When most code is AI-generated, the quality of AI coding assistants will be critical.
What are the proper evaluation metrics and environments for a benchmark?
Evaluation metrics for code generation tasks include code correctness, functionality, readability, and performance. Evaluation environments can be simulated or real-world, and may involve compiling and running generated code in multiple programming languages. The evaluation process involves three stages: initial review, final review, and quality control, with a team of internal independent auditors reviewing a percentage of the tasks.
External Links
- 1. “human-eval“, OpenAI, Accessed 23 September 2024.
- 2. “code generation“, Papers with Code, Accessed 23 September 2024.
- 3. “Command Injection“, OWASP, Accessed 25 September 2024.



Comments
Your email address will not be published. All fields are required.